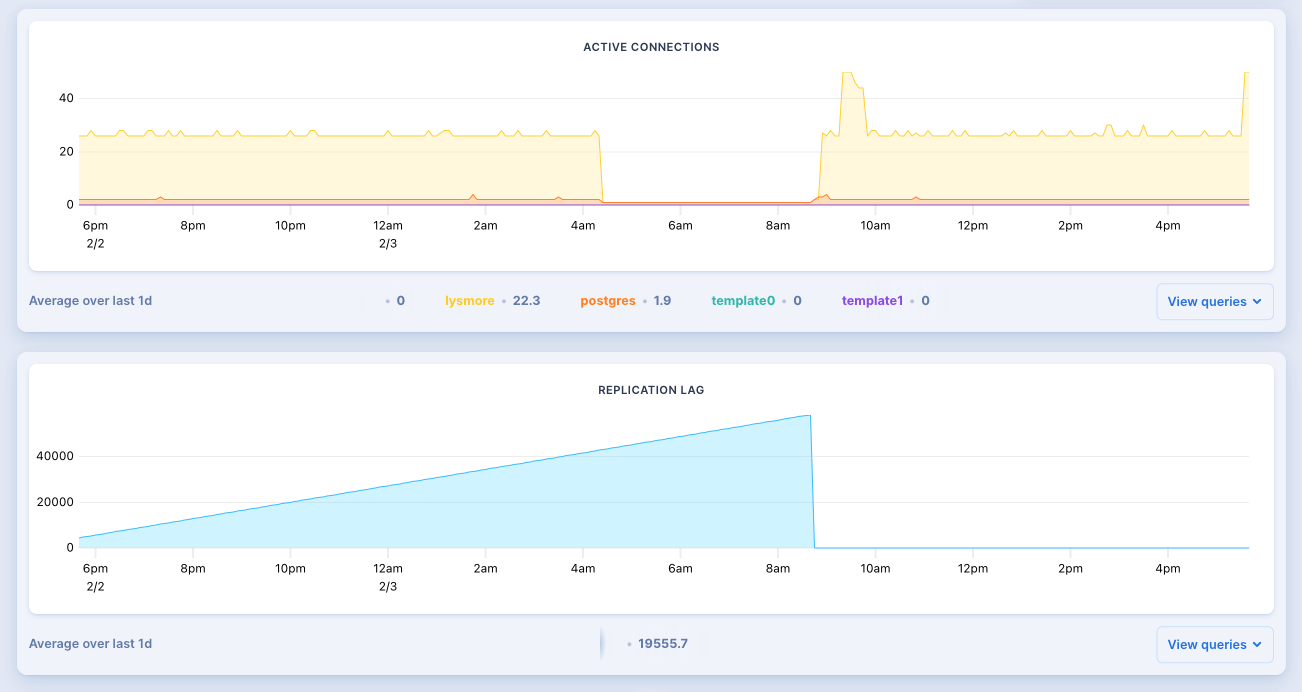
Last week on Thursday, instances 3rd, the Oban Web+Pro package repository
experienced a database outage. As a result of this outage, our customers
experienced 4 hours and 22 minutes of downtime where they were unable to fetch
oban_pro or oban_web packages. We'd like to apologize to our customers for
the impact on their daily operations—that's a large chunk of the workday.
Allow us explain what caused the outage, what happened during the outage, and what we are doing to help prevent events like this in the future.
What Happened
All times are in CST to match the metrics dashboard. Sorry, we prefer UTC too.
Our Postgres instances crashed around 4:34 CST and all database backed requests, e.g. repository license checks, started erroring. Shortly thereafter, the application itself crashed, and requests for static pages started failing as well. At 7:00 we discovered that the application was down, through multiple channels including Twitter, Slack, and various emails, we checked the metrics dashboard and immediately saw that the database crashed. We attempted to reboot the database to no avail.
The server logs eventually indicated that disk space was full for both the primary and secondary database volumes. Scaling to a larger database instance didn't have any effect. At this point we opened a community support ticket on the Fly forums and were pointed to a post that detailed how to swap to a larger database volume.
Around 8:00 CST we began the process of swapping from our primary database from 10GB volume up to 40GB. However, without any active servers running it wasn't clear which volume should be dropped to force a failover. Horrifically, we chose the wrong one:
$ fly status -a lysmore-database
ID STATUS HEALTH CHECKS RESTARTS CREATED
06cd9582 running (replica) 3 total, 2 passing, 1 critical 0 6m24s ago
13440ead running (failed to co) 3 total, 1 passing, 2 critical 0 12m1s ago
b585f97d running (failed to co) 3 total, 3 critical 1 30m5s ago
Fortunately, at that point, we had manual intervention from Fly staff. They restored the dropped volume, recovered disk space, and finished swapping over to newly provisioned volumes.
After that the database instances came back online, we were able to restart the app servers, and at 8:55 CST everything was running normally.
Why This Happened
Our database generated excess WAL (write ahead logs) that consumed all of the available space on our primary and secondary volumes. The volumes were 10GB each, while the database itself is only 250MB on disk and the metrics dashboard showed 3.7GB total VM usage:
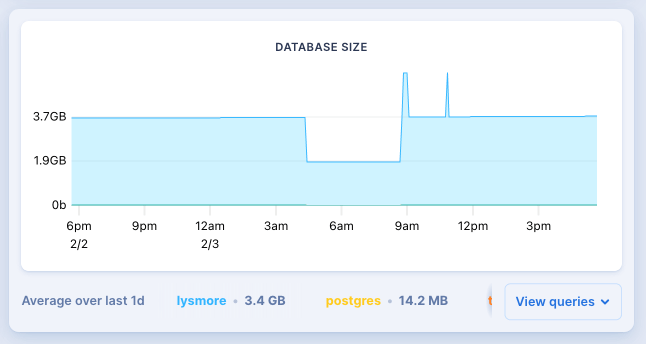
Despite the small database size, due to a high write workload, the WAL grew to 8GB. Once the database volume was out of space both postgres instances crashed and were unable to reboot. Our app's workload hasn't changed in recent months, so we're still investigating why the WAL suddenly grew so much.
While much of our application is static, including Pro and Web package hosting, any hex calls to the repository require a database call to verify an active license. That made the database a single point of failure.
Action Items
-
Over-Provision Postgres Volumes— We increased volume size from 10GB to 40GB and will leave the volumes heavily over-provisioned to stay on the safe side. Increasing the size of our database volumes was the first step toward mitigating the outage.
-
Caching & Circuit Breaking— We'll cache license lookup and wrap checks in a circuit breaker—it's better to serve a stale license than to crash! License checks are highly cacheable and shouldn't rely on database connectivity.
-
Multiple Regions—We'll replace the CDN as an edge-cache by hosting database-less applications in multiple regions. Until now we've relied on a CDN to get packages closer to our customers. That approach doesn't help when all requests route through a single server for license checks!
-
Parallel Instance—We'll stand up a parallel instance on entirely separate hosting to act as a backup if our primary cluster fails again. Fly's operations and multi-region support are amazing. Despite that, there are aspects of ops that are beyond our control without manual intervention from Fly.
-
Better Monitoring—We'll configure our uptime monitoring to check multiple endpoints, including one that verifies the database is alive. Our uptime monitor only checked the homepage, which is static and remained up long after the database crashed.
-
Metric Based Alarms—We'll integrate with an external metrics provider, e.g. Grafana, to set alerts for critical metrics like disk usage. Fly, our hosting provider, exposes Prometheus metrics for all operations, but there aren't any alerting mechanisms built in.
What We've Learned
People rely on our infrastructure for their daily operations. Serving packages is critical to our customers and we take it seriously. Despite considerable inconvenience, everyone was amazingly understanding and supportive.
Many thanks for trusting Oban and partnering with us 💛.
As usual, if you have any questions or comments, ask in the Elixir Forum or the #oban channel on Elixir Slack. For future announcements and insight into what we're working on next, subscribe to our newsletter.